The VoxTube is a multilingual speaker recognition dataset collected from the CC BY 4.0 YouTube videos. It includes more than 5.000 speakers pronouncing more than 4 million utterances in more than 10 languages. The work is conducted by ID R&D Inc. For the collection and filtering details please see [1].
Data description
| Dataset properties | Stats |
|---|---|
| # of POI | 5.040 |
| # of videos | 306.248 |
| # of segments | 4.439.888 |
| # of hours | 4.933 |
| Avg # of videos per POI | 61 |
| Avg # of segments per POI | 881 |
| Avg length of segments (sec) | 4 |
Language and gender distributions
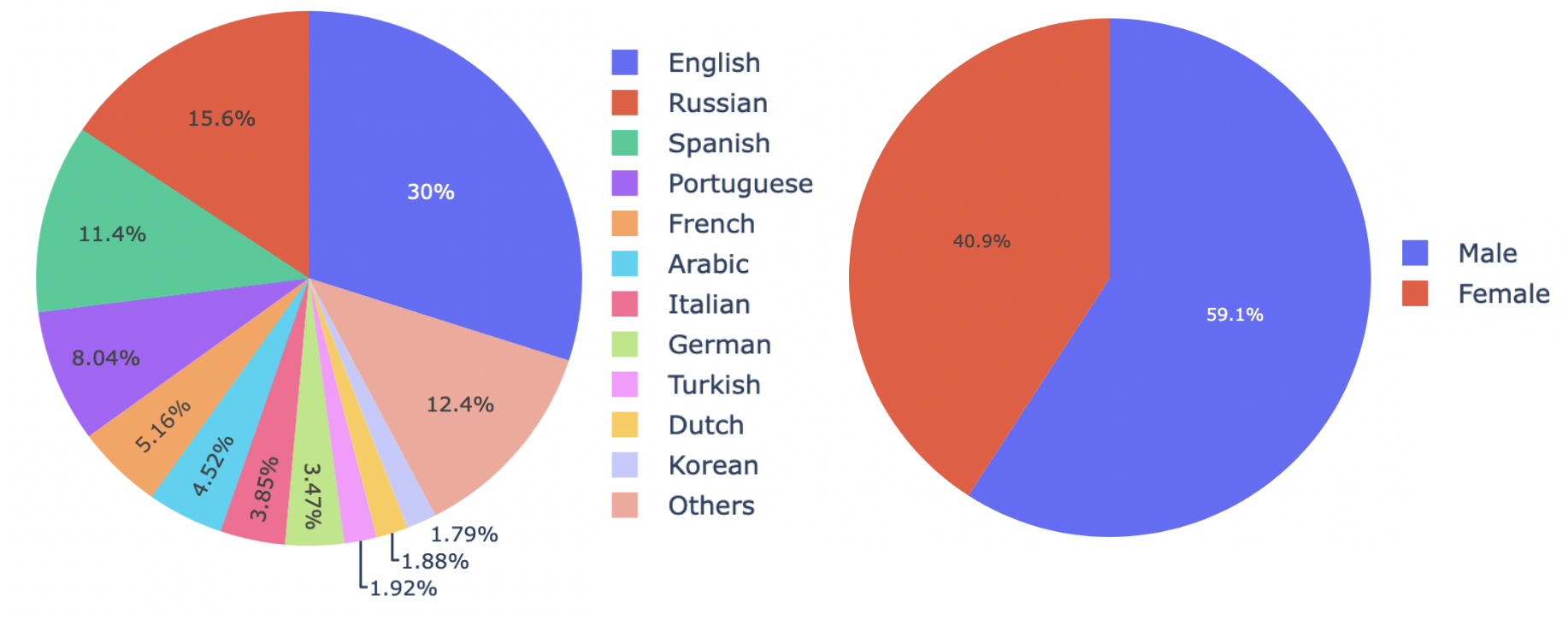
Labels for the language and gender of each speaker could be found here.
Data downloading and examples
Please go to the examples page.
License
The dataset is licensed under CC BY-NC-SA 4.0, please see the complete version of the license.
Please also note that the provided metadata is relevant on the February 2023 and the corresponding CC BY 4.0 video licenses are valid on that date. ID R&D Inc. is not responsible for changed video license type or if the video was deleted from the YouTube platform. If you want your channel meta to be deleted from the dataset, please contact us with a topic “VoxTube change request”.
Development
This is a live repository, so any changes to the dataset metadata could be proposed via opening the pull request.
Citation
Please cite the paper below if you make use of the dataset:
[1] Yakovlev, I., Okhotnikov, A., Torgashov, N., Makarov, R., Voevodin, Y., Simonchik, K. (2023)
VoxTube: a multilingual speaker recognition dataset.
Proc. INTERSPEECH 2023, 2238-2242, doi: 10.21437/Interspeech.2023-1083